
艺恩观察:视频AI训练数据告急:公网视频"吃完了",下一批从哪来?
当Sora 2、可灵3.0、Veo 3.1等前沿视频生成模型加速迭代时,一个被行业刻意回避的问题正在浮出水面——训练数据从哪来?
OpenAI在Sora 2的系统卡里仅用41个字描述训练数据来源,未披露任何数据集名称与规模。同期,NVIDIA Cosmos亮出2000万小时、9000万亿token的训练规模,腾讯HunyuanVideo公开了亿级切片的训练流程——前沿模型跑得越快,"用什么训的"反而越说不清。
多模态数据集服务商艺恩在近日发布的行业观察中指出:对任何一家正在做视频生成或世界模型的公司来说,真正的问题不是"下一代模型要多大",而是"下一批训练数据从哪儿来"。
瓶颈一:公开数据正在见底
Epoch AI在2024年ICML论文中估算,经质量修正后的公开人类文本约300万亿token,按当前消耗速度将在2026至2032年间用完。视频领域虽无等价研究,但可反向推算:NVIDIA Cosmos的2000万小时训练语料,大致相当于YouTube全球27天的全部上传量。
公网视频不是不够多,是不够好。质量、密度、信号均不足以支撑下一代模型。Meta V-JEPA 2训练用了"100万小时以上互联网视频加少量交互数据"——前一项是已做到的规模,后一项才是真正的瓶颈。
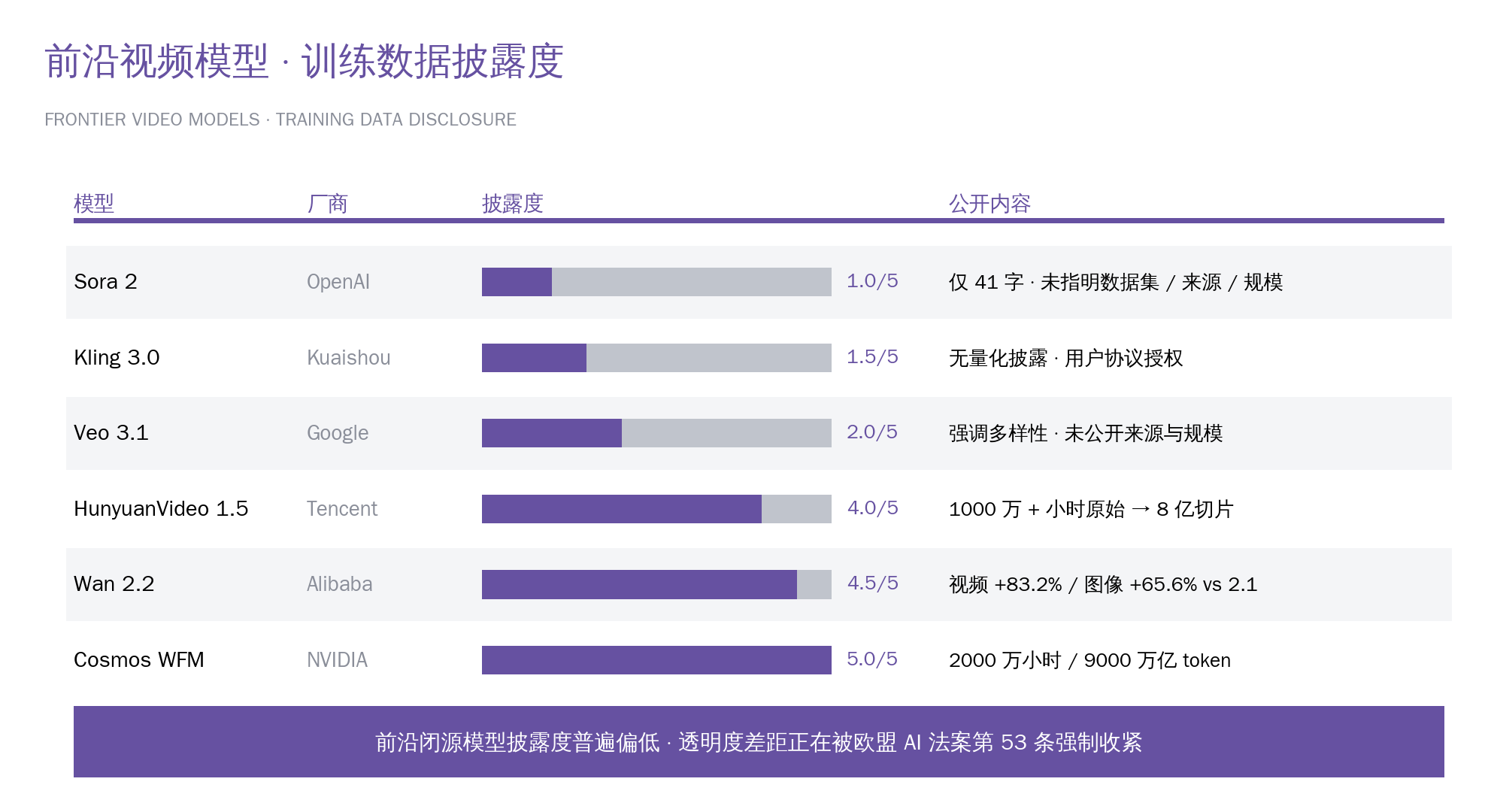
图 1 · 前沿视频模型训练数据公开披露度对比
瓶颈二:4D与多视角数据,公网里几乎没有
世界模型阵营已将此点明。Meta LeCun在V-JEPA 2论文中指出,"以观察为主学习世界"需结合互联网视频与交互数据;斯坦福Fei-Fei Li更直言:"空间智能的数据都在我们脑子里,不像语言可直接获取。"
目前公开4D数据集规模有限——上海AI Lab的DNA-Rendering提供6750万帧多视角语料,Google Stereo4D挖出11万个4D片段——相比千万小时级2D视频,小两到三个数量级,且高度集中在人体、自动驾驶、室内机器人三个窄域。
资本已用脚投票。2026年初,Fei-Fei Li的World Labs获10亿美元融资,LeCun创立的AMI Labs完成10.3亿美元种子轮,两笔合计20亿美元,核心押注均指向——为"理解物理世界"准备数据。

图 2 · 视频训练数据的三个结构性缺口
瓶颈三:电影级数据开始被定价
带导演意图的视频正在成为稀缺资源。阿里Wan 2.2按光线、色调、构图等几十维标注训练数据;Google Veo 3红队报告显示其输出"偏电影级,常出现切镜与戏剧性运镜"——背后必有高占比电影级语料支撑。
2025年12月,迪士尼以10亿美元入股OpenAI,200余个IP角色被纳入Sora生成范围,虽仅授权"输出生成权"而非"训练权",但这是好莱坞与视频AI首次以IP+现金+股权方式将内容摆上谈判桌。
国内方面,2025年1月爱奇艺起诉MiniMax的版权案仍在审理,索赔仅10万元,但作为中国首例视频平台诉AI模型案,信号意义远超金额本身。
艺恩判断:下一步不在公网
艺恩在观察中给出明确判断:"再加10倍数据"的方向,不在公网,而在三条路——
第一条是仿真合成路线,以NVIDIA Cosmos为代表,用物理仿真与机器人采集数据替代真实视频;
第二条是精标注路线,以Wan 2.2为代表,给现有视频叠加电影级结构化标注;
第三条是IP采购路线,以迪士尼-OpenAI为代表,真金白银买入版权清晰的优质内容。
三条路有一个共同特征:垂类、有授权链、有结构化标注。 艺恩认为,这已不是数据工程问题,而是战略采购问题——决定它的不是工程团队的吞吐能力,而是组织能否搭出一条"合规可溯源+多模态标注+持续更新"的供给体系。

图 3 · 2025-2026 围绕「视频训练数据」的资本与合规节点
艺恩方面表示,其在影视综艺、社媒、电商领域有超过10年的垂类数据积累,包括2.3B+条垂类视频资产、1.2M+部影视综艺授权片,以及多机位与4D采集能力和五维稠密标注体系。在其看来,行业面临的不是"数据用完了",而是"数据该被重新定义"——下一代视频模型需要的不是更多公网视频,而是更结构化、更可溯源、更接近真实物理世界的垂类语料。
文章来源用户投稿,转载请注明出处:/hangye/62557.html
